第二节 t分布
从数理统计的理论上讲,并且上节的实例也已说明,在总体均数为μ,总体标准差为σ的正态总体中随机抽取n相等的许多样本,分别算出样本均数,这些样本均数呈正态分布。而当样本含量n不太小时,即使总体不呈正态分布,样本均数的分布也接近正态。在下式中,
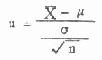
由于μ与(样本均数的标准差)都是常量,又
X呈正态分布,所以u
也呈正态分布。但实际上总体标准差往往是不知道的,上式分母中的σ要由S替代,成为
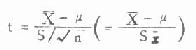
准差有抽样波动,SX也有抽样波动,于是,在用S代替σ
后上式等号右边的变量便不呈正态分布而呈t分布,其定义公式是
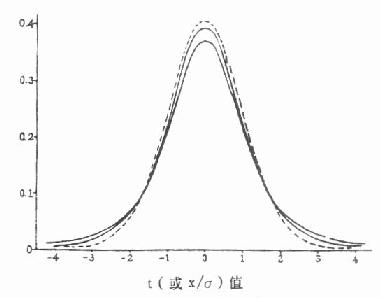
t分布也是左右对称,但在总体均数附近的面积较正态分布的少些,两端尾部的面积则比正态分布的多些。t分布曲线随自由度而不同(如图6.1)。随着自由度的增大,t分布逐渐接近正态分布,当自由度为无限大时,t分布成为正态分布。
图6.1 t分布(实线)与正态分布(虚线)
与正态分布相似,我们把t分布左右两端尾部面积之和α=0.05(即每侧尾部面积为0.025)相应的t值称为5%界,符号为t0.05,,,这里ν是自由度。把左右两端尾部面积之和α为0.01相应的t值称为1%界,符号为t0.01,,。t的5%界与1%界可查附表3,t值表。例如当自由度为10-1=9时,t0.05,9=2.262,t0.01,9=3.250。