��¼�塡�������в�ѧ�йؼ���
��һ��OR��ORMH�Ŀ�����ORi�����Լ���
��Miettinen���������������Լ���Ϊ�����ģ�test-based�������ޡ�����ORMH��100��1-������������ʽ

�˹�ʽͬ�������ڼ��㵥��OR������һ���ĸ�����������OR���Ŀ����ޡ���ʱ����ʽ����OR����ORMH����x2����X2Mh��ƥ�����ݵ�ORҲ��ͬ�����㡣�ú����͵��Ӽ��������㣬���ܼ�
ʽ�е�U���ɲ����̬����������5-1����U��/2�ɲ��/2��������U��ֵ����õ�95�������ް���ʽ���㣨����ΪORU����OR������ΪORL��OR��:
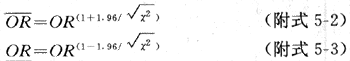
��¼5-1������̬����
| ������£� | �������ʱU��(��U��*) | ˫�����ʱU�� |
| 0.001 | 3.09 | 3.29 |
| 0.005 | 2.58 | 2.81 |
| 0.010 | 2.33 | 2.58 |
| 0.025 | 1.96 | 2.24 |
| 0.05 | 1.64 | 1.96 |
| 0.10 | 1.28 | 1.64 |
| 0.20 | 0.84 | 1.28 |
| 0.30 | 0.52 | 1.04 |
* ˫�����ʱU��ֵ�뵥�����ʱ��ͬ
����ʵ������4-4�����ݣ�ORMH��5.55��x2MH��76.84��95�������ޣ�
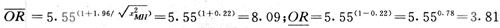
2. Woolf��������Ȼ����ת����
��1)���Ȱ�ORת��Ϊ��Ȼ��������ΪlnOR��
(2)����ʽ���lnOR�ķ����ΪV��r(lnOR)��

���ĸ����ÿһ����ֵ�ĵ���֮�͡�����ijһ�����ֵΪ0ʱ������ÿ�����ֵ�ϸ���0.5����������ǵĵ���֮�͡�
��lnOR��100(1-��)��������Ϊ
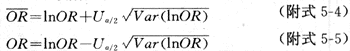
��Ϊ��95�������ޣ�������ʽ��U��/2��1.96��
(4)����ȡ�䷴������eX������ΪOR�Ŀ����ޡ�
(5)Ҳ��ֱ������ʽ������ޣ�

���϶������ڼ��㲻�ֲ�OR����OR���Ĺ�ʽ����Ϊ�ֲ������Ҳ����Woolf���������lnORi�ļ�Ȩƽ������������ޣ�ͬʱ�ɼ������ORi�Ƿ������ԣ����Ƿ�û���������죬�������ԣ������ܵ�OR�������塣
����ʵ�������ñ�4-4�����ݣ��ù�ʽ����ʽ5-4���루��ʽ5-5���ֱ�����������벻������������������ʳ�ܰ���OR���������lnOR���Լ�lnOR�ķ���ͷ���ĵ�����wiȨ�أ�������б����£�

�ܵ�OR����ʽ���㣺

���ϱ����ݴ��룺

�����ORMH(5.55)�൱�ӽ����ٰ���ʽ��OR�ı���

��Sx(lnOR)=0.2169,����lnOR��95��������lnOR��1.96Sx,�����2.09��1.24������
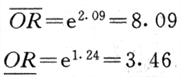
��ORMH��95�������ޣ�8.09,3.81��Ҳʮ�ֽӽ���
���Ǹ����ORi������⣬���������벻��������������ʳ�ܰ���ϵǿ�Ȳ���ϴ����ֲ������������Ļ����ж��������ʽ��x2���飺

ʽ��k�����������ɶȣ�k��1��
���뱾�����ݣ�x2��5.06��5.06>x2(1��0.025)��p<0.025��������OR��������������ͬһ����Ŀ����Ժ�С�������ܵ�OR����˵�����̡�������ʳ�ܰ�����ϵ�������������ġ�
����x2����ͬʱ��������������ؼ��Ƿ���ڽ������á������Ľ����ʾ��������ʳ������������ʳ�ܰ�Σ�նȵ���ϵ�н������á�
�������ַ�����õĶ����ƿ����ޣ�����OR������Чֵ�ŵ�����£��ر����������ϴ�ʱ�����Ʒ��뾫ȷ�����ý��ʮ�ֽӽ���
�� ƥ�����ݵ�OR������
����Miettinen�����������Լ���Ϊ�����ķ�������ʽ����ʽ5-1������ʵ���������±�4-11�����ݷ���������������������
(1)���㷽�

(2)OR �ģ�1��������������

����ʵ�������ñ�4-11�����ݣ�����OR��95�������ޡ�U��/2��1.96��OR��1.71��Var(lnOR)��(60��35)/(60��35)��0.0452��

������ù�ʽ����ʽ5-1����õģ�1.14��2.57���ܽӽ������������ϸ�ǡ����
���������������о����������Ĺ���
��ν��������������ָ������һ�������µ�һ�����Թ������������䶯ʱ����������֮�����仯������ֻ��������壬�����ܿ����DZ�֤�ɴﵽĿ�ĵ�ȷ��ֵ��
����������n���Ĺ�������ݢٶ�����Ⱥ��Ԥ����¶�ʣ�p0���ڱ�¶�뼲������ϵ�̶ȣ���RRΪָ�ꣻ�ۼ������ʣ��������������ܼ������ʣ����������¡�
1.��ƥ����Ʋ���������������ʱÿ����������
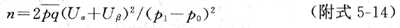
ʽ��P1��P0RR/[1��P0(RR��1)]��p��0.5(P1��P0)��q��1��P0��U����U���ɲ鸽��5-1����ʱҲ�ɲ��ù�ʽ��ͨ��������ɵ�n�����總��5-2��
����5-2�����������о�������������ƥ�䣬��������
�������������ʱÿ����Ҫ������
| ����0.05��˫�ࣩ���£�0.10 | ||||||||||||
| RR | p0 | |||||||||||
| 0.01 | 0.05 | 0.1 | 0.2 | 0.4 | 0.5 | 0.6 | 0.8 | 0.9 | ||||
| 0.1 | 1420 | 279 | 137 | 66 | 31 | 24 | 20 | 18 | 23 | |||
| 0.5 | 6323 | 1286 | 658 | 347 | 203 | 182 | 176 | 229 | 378 | |||
| 2.0 | 3206 | 689 | 378 | 229 | 176 | 182 | 203 | 347 | 658 | |||
| 3.0 | 1074 | 236 | 133 | 85 | 71 | 77 | 89 | 163 | 319 | |||
| 4.0 | 599 | 134 | 77 | 51 | 46 | 51 | 61 | 117 | 232 | |||
| 5.0 | 406 | 92 | 54 | 37 | 35 | 40 | 48 | 96 | 194 | |||
| 10.0 | 150 | 36 | 23 | 18 | 20 | 24 | 31 | 66 | 137 | |||
| 20.0 | 56 | 18 | 12 | 11 | 14 | 18 | 24 | 54 | 115 | |||
(��¼��Schlesselman,1982)
�����������һ������յ��飬�о�������ΰ��Ĺ�ϵ��Ԥ�������ߵ����Σ�ն�Ϊ10.0����Ⱥ������Լ0.4���趨����0.05��˫����飩���£�0.10������ɼ������財������ո�20��������С����RR�ܴ����ù�ʽ����ʽ5-14�����㣬����Ҳ�������n��22�������г����Ǽ���ʱ����С��λ����ͬ���¡�
�ڦ���0.05��˫����飩ʱ��Ua��1.96���£�0.10��U�£�1.28������ʽ����ʽ5-14���ɼ�Ϊ

2. ��ƥ����Ʋ����������������ʱ
�裺��������������1:c������Ҫ�IJ�����

ʽ�У�

��������cn��
3.��1:1ƥ�䣨��ԣ���ơ���ӹ��ƵIJ������������Dz�������ձ�¶�����ͬ�Ķ�����������4-10�е�f10��f01������Ϊm����
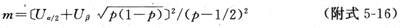
ʽ��P
��Ҫ���ܶ�����f11��f10��f01��f00����ΪM����

ʽ��p1��p0RR/�z1��p0(RR-1)�{��q1��1-p1��q0��1-p0
��������ձ�¶��p0��0.3������0.05���£�0.1��Ϊ���RR��2��Ҫ��
m��[1.96/2��1.28
�����������о���ʵ�����о�������������
ʵ�����о�������о������֮ͬ�������Զ������������Ĺ���һ�����ܡ�
1.�����о���������������ֻ�м������ϵ������������ơ�Ӧ�ù�ʽ����ʱ������Ա�¶����ʵ�����о�Ϊ������Ԥ����ɵ��������IJ����һ������������ʽ��p0Ϊδ��¶����¼�����������p1Ϊ��¶����¼�������������������������Ծ�������ۣ����涨���ͻ�������ĸ��ʣ�����£���
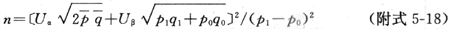
��Ϊ��ʽ����ʽ5-14����ԭʽ������ʽ5-14�������ʽ�����ŵ�������ʽ��ͬ��ʵ�����о���ʱ������С��Ӧ�ñ�ʽʱҪ���¼����������������0.2����0.8��
2.ʵ�����о�������ʽ����ʽ5-18���⣬�������ʵķ�����ת�������������¼���������0.05��0.95֮�䣬������顣����˫����飬���æ�/2����ʽ�еĦ���
(1)ʵ����������nt����������������nc����ȡ�

nt��nc��
ʽ��pc��������ٶ����¼�������
pt��������ٶ����¼������ʡ�
U����U��ֵ�鸽��5-1��
(2)ʵ������������������ȣ�nt/nc��1��Ϊ�ˣ�

nt����nc��N��nt��nc����1������ʵ����ʱ����Ϊ���飩��N����nt��nc��
������ʽ���ʵ�ƽ�����ķ����ң�sin-1��arcsin�������Ҷ�����ʾ�ģ����ú����ͼ�������RAD��ʽֱ�Ӽ��㣬ʮ�ַ��㡣
����ʵ�����������Ϊʵ������������һ��������Ϊ�ⶨ�Ľ�֣������5�꣬���౸����裬pc��0.40��������5�������ʣ���pc��pt��0.10������0.05����=0.05���ˣ�1������ʽ����ʽ5-19����
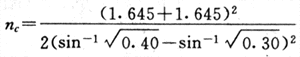
nc��491��nt��491��N��������������nc��nt��982��
��ʵ�ʹ����л�Ӧ����ʧ�á��˳��������ӵ���������ɵ����������٣��ڹ���ʱӦ�����ʵ�����������ʧ��Ϊd������ϵ��1/(1��d)��nc��������������d��20������nc��(1/0.8)��491��614��nt��614��N��1228��
�������ù�ʽ����ʽ5-18�����㣬��nc��490������ʧ�ʣ�d����20������nc��(1/0.8)��491��613��nt��613��N��1226���ɼ��������û���һ�£����Է�����ת������Ϊ��㡣
���ģ�����֪�������������ܲ����������Σ�ն�
һ�ֳ���������������������������Ѿ������о��������һ����������ܹ���һ���İ��նȲ�������Σ�ն�����Ƕ��٣���Ϊ����������Ϊ��С�����Σ�նȣ��������Ԥ�Ƶ���ؽϴ���Ӧ������������ٽ��з���������ͽ�͡�
������ʽ���ƣ�ʽ��nΪÿ��������p0�������µ�������빫ʽ����ʽ5-14����ͬ��

ʽ��
A��(U����U��)2
B��1��2p0
C��2p0�zn(1��p0)��Ap0�{